

Trust : ” a firm belief in the reliability, truth, ability, or strength of someone or something”
In this post we are going to take a simplistic look at an organizations trust relationships, i.e “how to make trust decisions”, Then attempt to describe this in a learning model.
Lets start with some questions to frame our task.
How do we define trust in a system? How do we determine trust? How do our responses change when we trust something? How do we respond when we don’t trust something?
We are going to attempt to formulate an observation model that we can use to learn the answer to some of these questions. So for this exercise we are going to be setting our focus on observing the response to the identity rather than the identity it self.
How do we define trust in a system
If we treat trust as a simple binary classification problem. True or false, we can work backwards from fundamental access requirements and establish rules and conditional logic that will govern how a system response to a set of identity attributes. Organizations today are doing just this. They leverage business intelligence modeling tools, spend time and spend effort to automate and streamline their new employee on-boarding processes. (eq.., we study a process, design, program logic that is coupled to that process, implement, reassess.) Over time this requires revisiting and reprogramming of the model to keep it relevant.
This approach works from a linear process efficiency standpoint, but if we want to gain a deeper understanding of trust, I believe we need to take a different approach and this is where machine learning can assist us.
The core problem with this classic model is that the rules that where derived from the original upfront assessment and analysis. These rules become obsolete over time, their change driven by requirements both internal(business lines, partners, etc.) and external(regulations, changing markets, etc.). Time and resource are required to continuously reassess and update these models. Also these models are typically not general and have to be customized, sometimes even completely redeveloped for new uses-cases.
On the other hand, if we build a ML that can observe the process, generate rules, reinforce those rules, and discover why rules are different, we can develop a new model. A model that is not just a one use-case answer, but an adaptive dynamic model capable of answering unprogrammed use-cases, and even perhaps future yet to be discovered ones.
How do we determine trust
It is an iterative process that starts long before someone request data, or is hired. It starts with the individual establishing their identity with a local governing body. In the United states this is primarily the job of the State government and in some cases the Federal government (see, Passports, Real ID act). They establish identity by evaluating official records, such as a birth certificate, and supporting documents from other organizations. One after the other building a foundation of trust in the person’s identity.
The individual then adds to their identity by establishing some type of communication channel that they can use to interact with other parties. In the past this was a phone number and mailing address. Nowadays it includes an e-mail, and this is interesting because this is the start of a individuals personal digital identity. I say personal because most organizations will establish the digital identity of the user in their own systems (HR records, IT accounts and business email)
In 2017 NIST published Digital Identity Guidelines, laying out guidelines for
“federal agencies implementing digital identity services.. guidelines cover identity proofing and authentication of users (such as employees, contractors, or private individuals) interacting with government IT systems..”
Though these guidelines are intended for the federal government, the core concepts of “Identity assurance” and “Authenticator assurance” are applicable across all industries. These guidelines put a users personal e-mail at Identity Assurance Level (IAL) 1, meaning that no 2nd party has validated its connection to a real world identity. NIST has gone as far as to say that 2-step verification(SMS) and association with a MFA device is not valid for proof of identity and is only “self-asserted, or should be treated as such”.
In the U.S new employees will go through an “I-9 process to validate their identity“, after which their corporate digital identities will then be considered at a higher IAL. This works for employees, but what about third parties, partners, media outlets, customers, etc.. that need access to data? This is another opportunity for centralized Identity management.
This leads to the next and possibly most neglected and misunderstood aspect in determining trust; how we apply it to a data system.
Right now organizations have rules on how employees, vendors, admins, and even the owner of the company gets access to data. In some cases this knowledge only exists inside the minds of the system administrators, or written out in vague archaic memos and policies. Nonetheless, rules are in place and they are being enforced and followed to some degree. This web of knowledge can be very valuable in understating why a trust entity receives different access.
This leads to another NIST contribution, the “Policy Machine” and it implications for mapping attributes to access rules, “Attribute Based Access Control“. This is going to be one of the keys to success in the mission to build a machine learning model for user trust. I will discuss this more in the next post “learning how to learn”, even a generalized A.I may need some pre-education to be successful.
What do we do when we trust something? What do we do when we don’t trust something?
A response to a data access request typically goes something like this. Administrator evaluation a set of documented access requirements and access request. Then compares them against the presented user credentials and\or qualifications(attributes), and in most cases against a set of “undocumented requirements”.
Why do they need access? What department?, For how long, Who is their supervisor, etc.., even bias and intuition play a factor. There is more to the question of “Why do they need access” then “to do their job”, in a complex system this can drive logic about what access they need in order “to do their job”. This can be time consuming and if not properly mapped, data access mistakes can be made.
Based on all of these attributes and rules both documented and undocumented considered together. Access may be granted, limited or denied all together.
What are these attributes, and how could we learn them and map them? Lets see if this could be done through knowledge transfer.
Human Observation
Where do we start. Let’s look at training, How do we train a new administrator today?
First we start with observation.

How do we reinforce that training?

A trainee will demonstrate their learned knowledge through practice, trainer will continue to teach the trainee by becoming the observer.
How do we translate this in to a machine learning process?
Machine Learning Analog
Lets take the training model from above and develop a high level process flow.
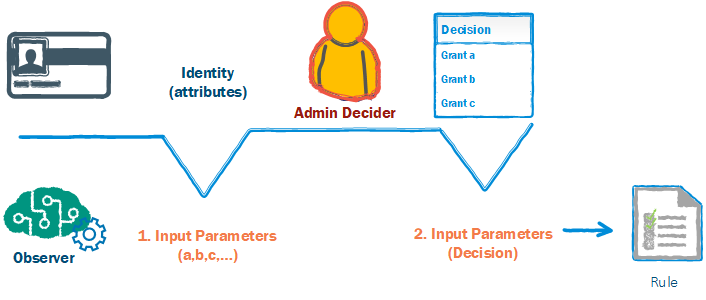
By placing the ML actor in-line and taking the place of the trainee, the ML can generate rules based off of the outcomes of observed transactions. Much like a human observer.
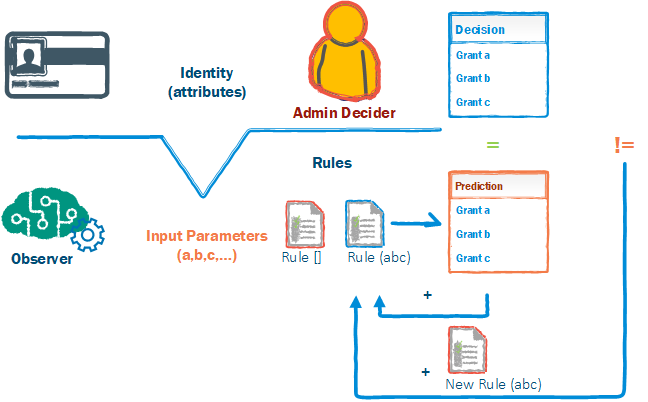
In the case of reinforcing rules, the ML process would evaluate the input and predict an outcome based off of probability of a learned rule. If the prediction was correct the weight of the rule would increase if the prediction was incorrect, a new rule would replace the old rule.
This works until we learn something new about the process?
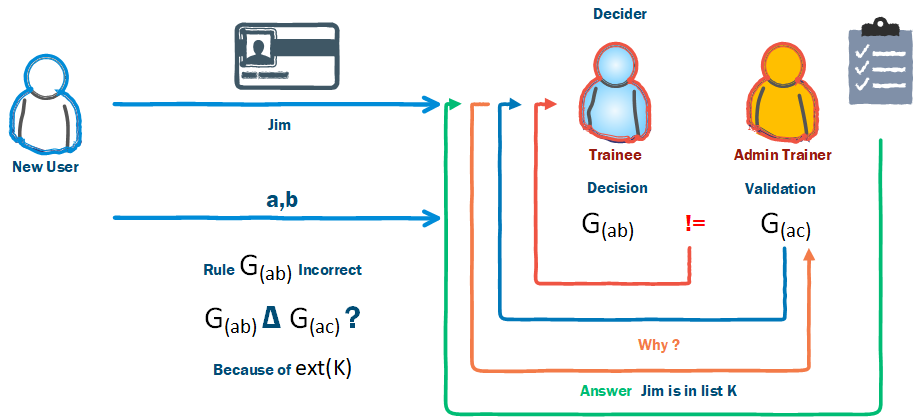
What happens when we learn something new?
The trainee will now incorporate this into their process and consult this list for names before making a decision. Further reinforcement will increase the likelihood that the trainee will make this decision in the future.
What about a machine?

A straight forward approach would be to treat the identity as a new parameter (a, b, c) -> (Id, a, b, c), and now respond to that Id with a unique Rule.
We need to stop here because we are beginning to fork the process now, and at this point we are losing generality and growing beyond simple observation.
We now have a new question would a ML learn this new parameter on its own? Could this be learned through only observation?
I believe the answer is possibly!
Though this has been proven through techniques like Deep Learning. A great example of which is DeepMind’s Capture the Flag (don’t let the fact this was done with computer games fool you.) This leads to a new set of issues, mainly the multitude of unique rules required and the multitude of data points required to create those useful rules. In this case it is the time it takes to collect those data points from the observation of human admins and users and for a single organization this equates to a long time.
We have to ask the question how does a human make these connections so quickly.
One answer is a human would simply ask why and incorporate the this new knowledge into their process. How could a ML process do this, is it metadata, is it perhaps meta-learning(learning within learning)?
In the next post “learning how to learn” we will take a step back and look at learning, how machines are learning and what perhaps is missing that could help make faster learning connections.