

We have all created multiple accounts in multiple systems (e-mail, social media, financial, utilities, etc..) All of these requiring an account to centralize your data inside their independent ecosystems.
An account is a requirement for organizations to provide us a service, which allows for the internally linking of contact and billing info, and services. An account is not an identity it is simply a record in a database. A static record that can go on for years with out being reviewed or updated independent of the changes to your real identity (phone, address, e-mail, etc..).

There is a greater issue here then obsolescence of data attributes. It is the inability to completely track the use of these accounts as identity impersonators. When we delegate an organization permission on our behalf to provide a service, or a recurring financial transaction, we have in a sense fractured part of our identity. We have taken a set of PII attributes + account name (our pseudoidentity), verified sometimes only by email and put it in action to preform a task. This is not federation, this is not true delegation, we can not centrally track and maintain what we have granted to these organizations. Though most companies do their best due diligence, we can not 100% guarantee that every organization will alert us when changes have been made to the use of these accounts.
This is greater then a personal data privacy issue. This is an all data issue and one organizations big and small have to deal with everyday. Corporate IT infrastructures rely on non human service accounts to preform delegated operations for databases, webservers, applications, and data transactions between third parties. Administrators and system designers are fracturing their identity, delegating permission to these systems & trusting that the logic encoded within them will always perform as expected. For the most part this is true, well designed rules can guarantee that a process is understandable and repeatable. Unfortunately, the task of interpreting, tracking, and auditing these rules is getting more complex and is only going to become more difficult as the autonomous systems we use become more intelligent.
As machine learning and A.I becomes more prevalent, we will have long running (existing) non human entity that will have access to corporate, government, and personal data. The complexity of these systems are far greater then the rules of the past. Therefore the need for “..Explainable AI”.
What if these individual accounts did not exist, what if instead you
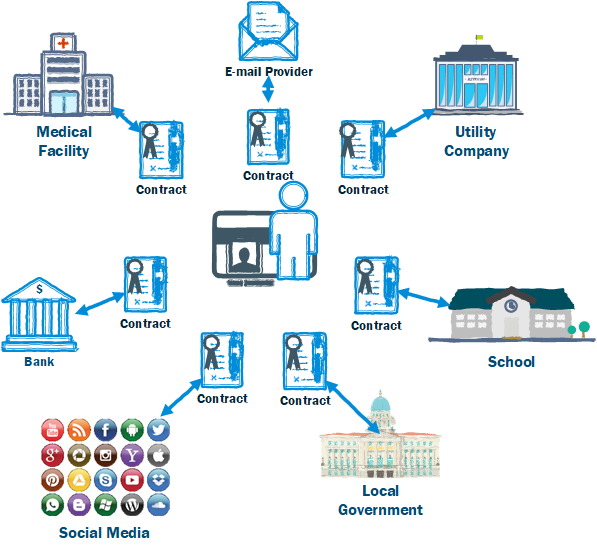
had just a single digital identity and contracts of delegated authority with these services ( between entities). Contracts that specified exactly what level of information is needed and for how long. Contracts that protect both the individual and the organization.
Here at Lavaca Scientific we believe that this is the future of the digital identity. Not just identity management, but a core independent identity. We believe that by leveraging blockchain’s decentralized and independently validated nature as the backbone for identity management. Users and organizations a like, will benefit from a less complicated and more secure identity ecosystem.
We are not alone in this belief, organization such as Decentralized Identify Foundation (DIF) and NIST have pioneered the way. By working to develop a “standards” to which all organizations will adopt to make this a reality.
This does not negate the need for Identity proofing, the core identity will still need to be validated. This though does hold the promise of reducing organizations costs and effort by de-duplicating identity proofing. For instance, eliminating background investigations and credit checks on the same individual with multiple accounts or by excepting through reciprocity the decision another entity has made about that identity.
Another promise this holds is cleaner lines of trust. This will make studying and observing interactions between entities easier, by the very nature of its “standards” communication protocol, data will be more available, interpretable, and general. These are all promising attributes for ingestion into machine learning algorithms.
In the next few weeks we will be talking about trust, learning trust, and why learning “how to learn” may be the next big step in machine learning for identity management.